Making a Tap-Conditioned Video Model
2026-03-14
Why touch (and why I like the term "interactive video" over "world models")
I was playing with DIAMOND (a diffusion world model for games) last year and kept coming back to a question: what if the control wasn't WASD but direct touch on the frame?
I think most of the energy around video world models is aimed at RL-style control loops and videogame-like interaction. This list is a good snapshot of the current ecosystem. That makes sense though, it's a well-scoped research problem. But to be honest, my motivation here isn't robot control or benchmarking agents :)
I'm coming at it from a media/art interface. I wanted something that feels like live video you can physically poke: disturb a tiny region, get a localized response, and keep going. I think "interactive video model" is the clearer description here, but I'll occasionally use "world model" since that's the term most people will recognize.
koi pond
I couldn't reuse existing datasets or record Doom/CS:GO to get tap-style interactions, so I thought the best place to source touch footage would be mobile games. I spent a couple days but couldn't find anything compelling, and the Android emulator/recording stack was a mess. So I just built the environment myself.
I only needed to know if this tap idea works after all. Most game environments come with a lot of stuff I didn't need at this point: discrete button actions, camera movement, HUD overlays. Touch-first interaction only needed a spatially local action space: "this (u, v) point in the frame was disturbed."
With the koi pond environment, I get:
- fixed camera, no navigation.
- one interaction: tap the water
- action is a spatial point in frame (plus strength)
- fish react by scattering away from the disturbance
spoiler: Turns out it's also a brutal rollout test. Water ripples occlude fish, fish cross each other, leave frame, and may never re-enter. If the model is even slightly unstable, fish stop looking like fish within seconds.
The rough model plan was:
- take the last 8 frames of the pond
- encode the tap location as a spatial heatmap
- predict the next frame (later: the next latent, then decode it back to pixels)
- feed that prediction back in as history
- repeat forever
Recording the data
The environment is a web-based sim I built in JavaScript. Being browser-based helped scale data recording in a short time. A headless recorder spins up parallel Chromium workers (Playwright), runs an auto-tap policy, and uploads chunks to a server.
Each chunk stores:
- 256x256 RGBA frames (15 FPS, 6 seconds)
- per-tick tap actions + metadata
- uploaded as
*_frames.bin+*_meta.json
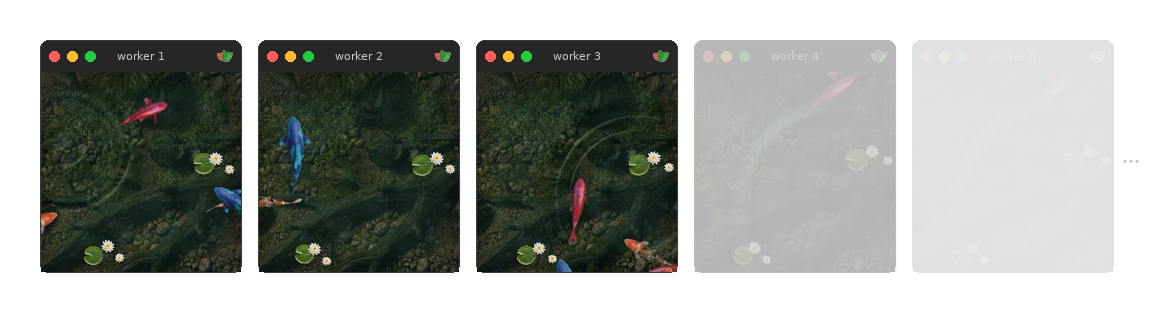
What the sim renders
- layered render: 2D background + WebGL water + 2D fish + 2D surface overlays
- fixed 256x256 base resolution and fixed tick rate (built for recording)
- fish are animated sprites + boids-ish steering, with an explicit "fear point" response to taps
- taps spawn water ripples
- water is a WebGL shader driven by ripple impulses;
Each tap has UV coordinates, so I can turn it into an action map aligned with the pond image. The action tensor is two channels: scare_heatmap and tap_flag. So if I tap near the top-left corner, it knows where in the frame the disturbance happened.
Version 0: the naive pixel baseline
I didn't immediately start with diffusion, and instead made a much simpler pixel-space predictor as a cheap sanity check - it was a small convolutional next-frame model trained directly in pixel space. It used a short history window and predicted future frames autoregressively.
It could keep the pond looking vaguely pond-like, but the fish quickly smeared into the background during rollouts. I pushed the rollout horizon from 8 to 32, which bought a little extra stability, but not enough. The model still collapsed too quickly to be interesting.
That was my first strong signal that plain pixel prediction was the wrong tool for this particular problem.
Moving to latent diffusion
I moved to latent diffusion because it trains faster and lets me run longer rollouts. The autoencoder compresses each frame down to a much smaller representation:
- image size:
256x256 - latent size:
32x32 - latent channels:
8
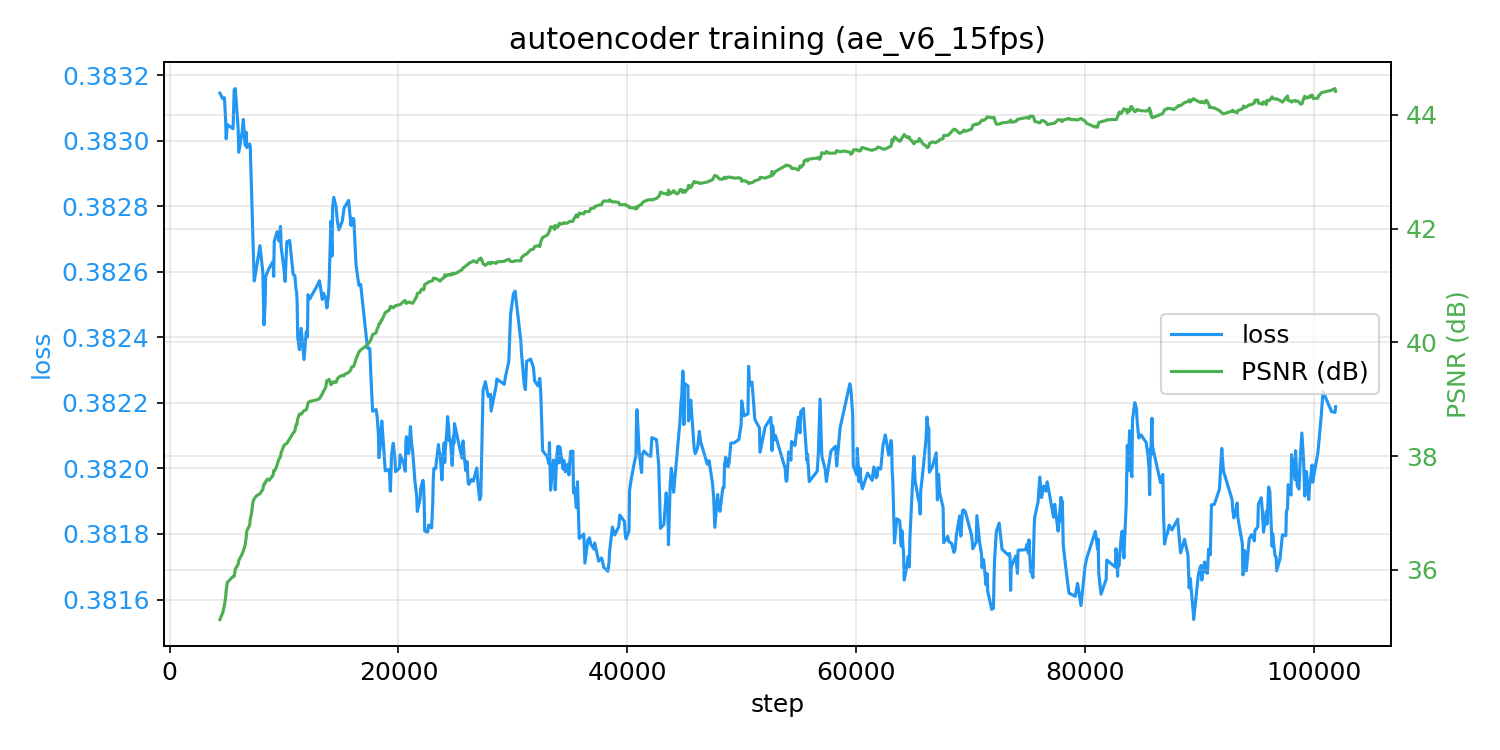
I trained the AE on the 15 FPS koi recordings, froze it, and reused the same one across all future WM runs.
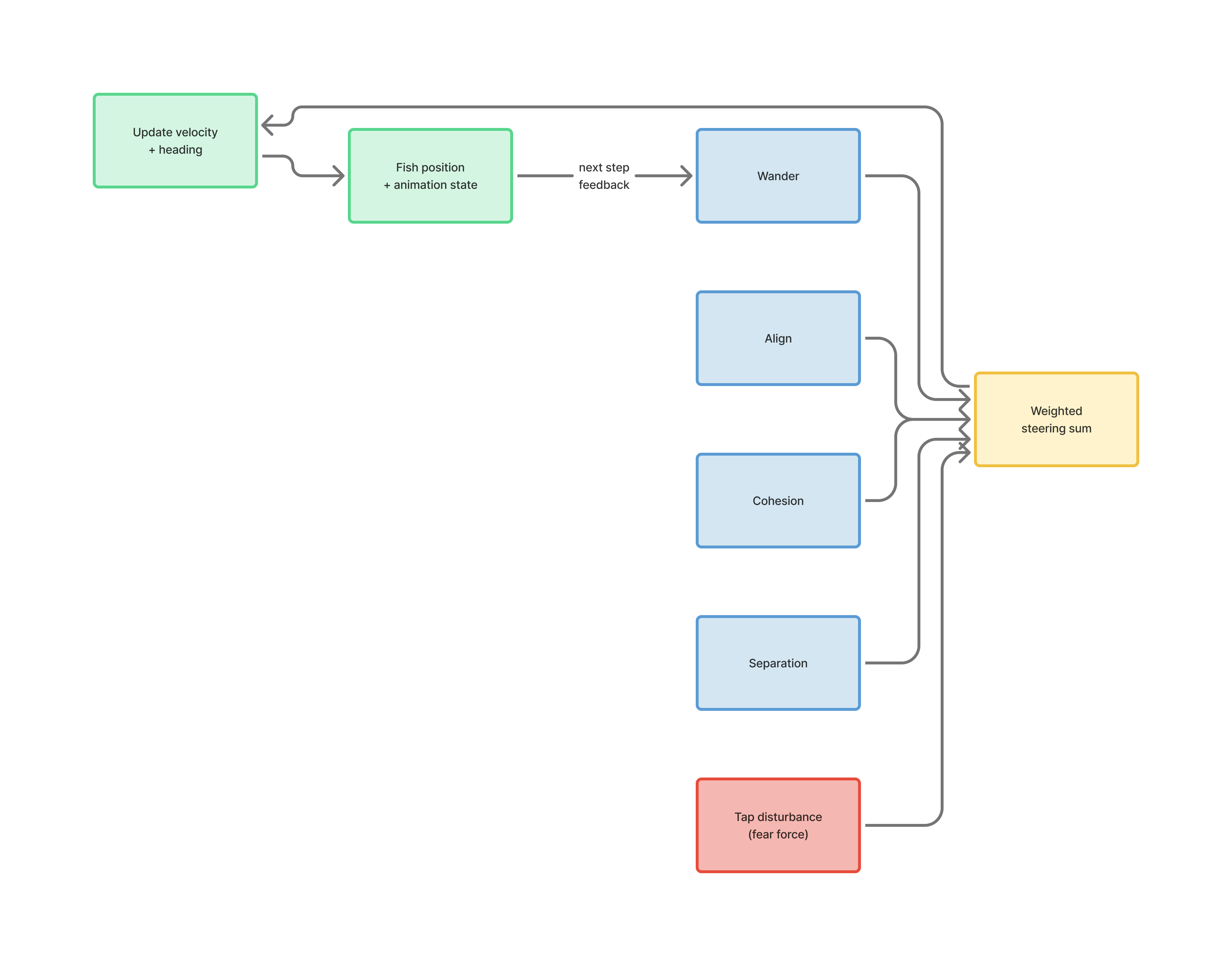
Once I had that, I trained the world model on top of it, so it takes:
- history latents
- action map channels
- optional noise-conditioning channels
and predicts the next latent frame.
The first model that worked
After a bunch of iterations on the latent diffusion setup, the first model that actually felt good was around my ninth run.
Latent EDM, history = 8, 15 FPS data, action conditioning via the spatial tap heatmap.
This was the point where I could show it to someone and they immediately get it.
The fish reacted to taps. The scene was stable enough to feel like a living pond rather than a repeated short clip. This also pushed me into deployment work. Once I could interact with the model continuously in a browser, I started seeing issues that were easy to miss in short offline rollouts.
The hard part: fish dissolving under rollout
The hardest problem in the project was temporal coherence. This is the train-inference mismatch (exposure bias): during training the model sees real frames as history, but at inference it only has its own predictions. Small errors compound and your frames turn to mush.
In practice it looked like this:
- fish start out sharp
- swim normally for a bit
- then slowly shrink, blur, or partially disappear
- ripple crossings make it worse
The frustrating part was that the model was often right locally. Frame-to-frame it looked plausible. But after enough steps, the fish would just drift away.
In the baseline setup, the model trains on clean history, but at inference it's stuck inside its own slightly wrong predictions. That gap is what kills the fish.
More experiments
Food-mode detour
I spent a while trying a dual-action version: one tap mode to scare fish away, another to attract them toward a point like dropping food. It was interesting, but it never became the better version of the project.
Expand: what happened in the food-mode branch
Once the scare-only demo was working, I extended taps to mean two different things: scare or food. That meant expanding the action tensor from 2 channels to 3 (scare heatmap, food heatmap, tap flag) and re-recording data with both modes alternating. This turned into a much bigger detour than I expected. The heatmap signal was basically disappearing. I was generating the action heatmaps at 256x256 and then downsampling them to the 32x32 latent grid. After interpolation, the peak value at latent scale was around 1e-4. For scare, the model could still latch onto it because the visual response was strong: ripples and fish scattering. For food, where the response was slower and subtler, that signal was too weak to matter. I eventually fixed this by generating the heatmaps directly at latent resolution, but a lot of the early training was already wasted. Food mode started to work, then stalled. After fixing the heatmap issue and retraining from scratch, I got some promising behavior around 80k steps. Fish would actually move toward the tap point. But after that it more or less plateaued. Another 70k steps didn't really buy much. My guess is that scare was just an easier signal to learn: it causes immediate, high-contrast motion, while food only shows up as a slower drift in fish behavior. The data mix also hurt. In some early runs, I mixed the new food dataset with the older scare-only data, where the food channel was always zero. That made it easier for the model to ignore food conditioning altogether. Even after removing the old data, it never fully caught up. I also tried using negative CFG as a shortcut, basically treating "approach food" as the inverse of "flee scare." That didn't work. The two behaviors just aren't visual opposites in any useful sense. I ended up doing three serious runs on this branch. It wasn't a waste, but none of them got close to the scare-only model in quality.The food branch added a lot of complexity without solving the thing that was actually holding the project back, which was temporal consistency. So I dropped it and went back to scare-only.
A lot of the best improvements ended up coming from fixing the data instead of changing the model. One example was chunk boundary leakage: ripples from the end of one chunk would spill into the start of the next, creating training examples where the model saw a disturbance with no matching action.
Closed-loop training
The first architecture change that actually moved the needle was rollout-2 closed-loop training: instead of always conditioning on ground-truth past frames, let the model condition on its own predicted latent for the next step and train it to keep going. Concretely, I unroll two steps during training, feed the first predicted latent back as context for step two, and optimize both steps together.
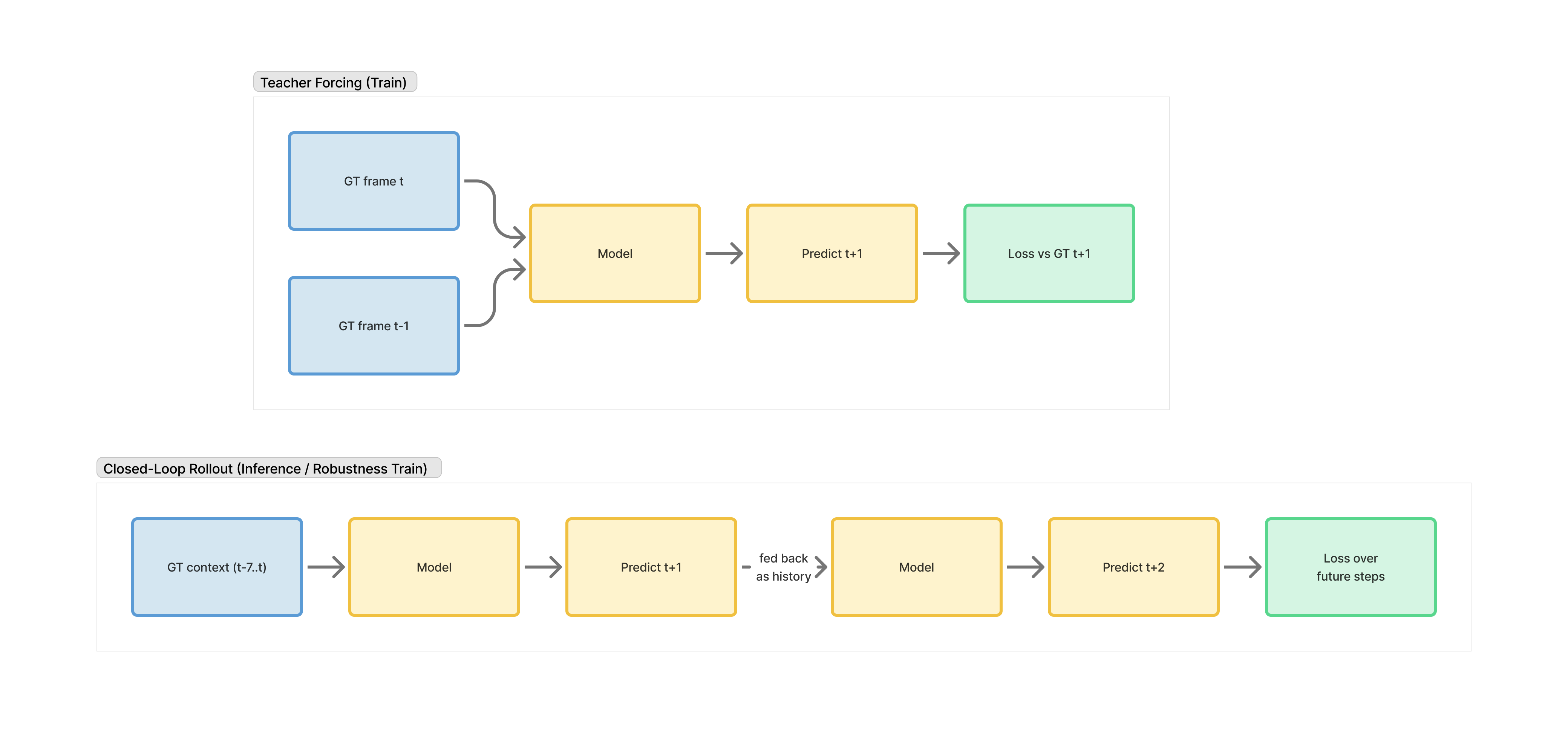
It's still a small rollout, but it changes the objective. The model isn't only judged in the easy teacher-forced regime anymore.
First time I tried this, fish survived ripple crossings way more often. It didn't solve everything, but it was the first result that made me think: ok, the core issue really is rollout robustness. Downside was training got slower.
More proof of diagnosis than final solution.
The final model
The final run combined everything instead of addressing issues one by one:
- rollout-2 closed-loop training
- cleaner recording hygiene
- quiet chunks with no taps, so the model also learns stable idle dynamics
On top of the denoising loss, I added a simple auxiliary delta-latent loss: instead of only asking "did you predict the right next latent," it also checks whether the predicted change between frames matches the real change. This penalizes things like fish teleporting or vanishing between steps, even if individual frames look fine on their own.
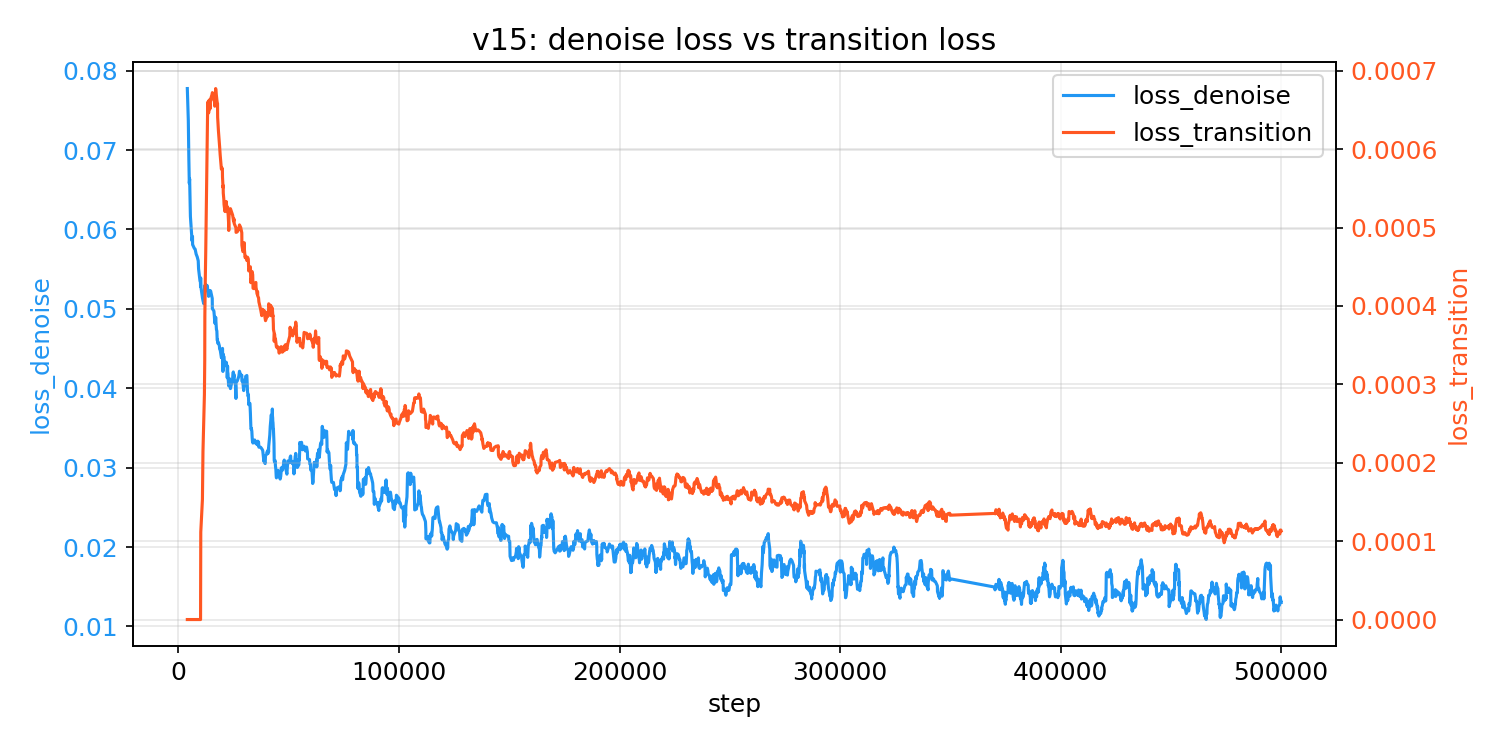
The result isn't perfect. I still see failure cases: fish vanishing mid-swim, long-horizon identity drifting, the pond being more stable than the fish.
But compared to the earlier branches, it feels much more like a real interactive world and much less like a fragile next-frame demo.
Here's the first working model side-by-side with the final one:
Architecture at a glance
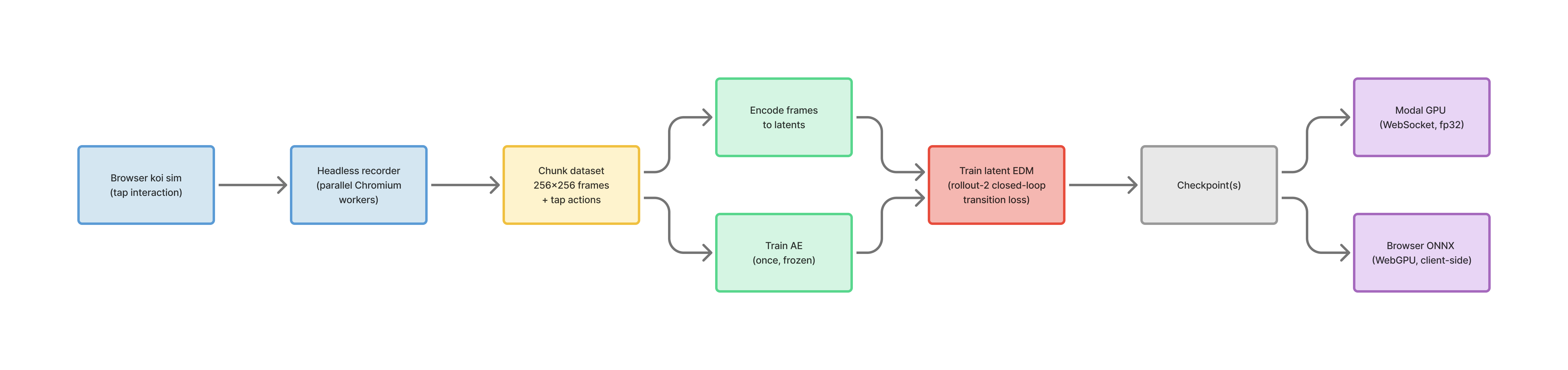
Data Recorder / environment
- browser koi simulation
- 256x256 RGBA frames
- 15 FPS
- tap actions stored with UV coordinates
Autoencoder
- compresses
256x256x3to32x32x8 - trained once and reused across many WM experiments
World model
- latent EDM / UNet-style denoiser
- history window of 8 frames
- action channels concatenated with history latents
- sigma conditioning available when noisy-context training is used
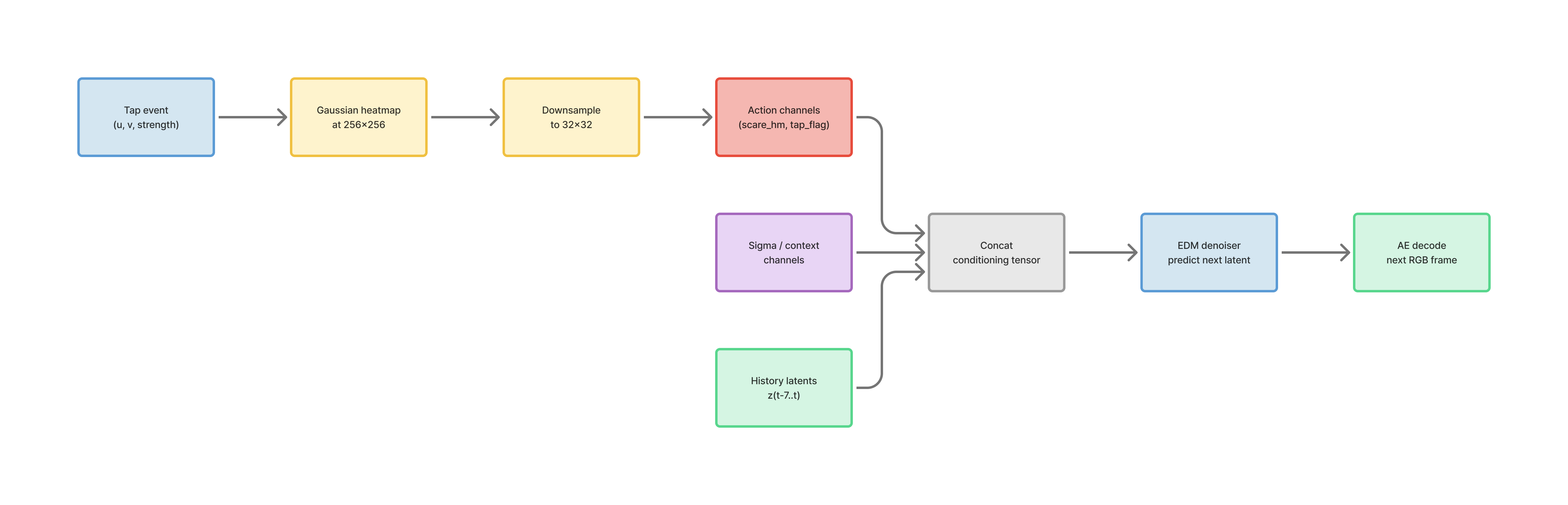
Action representation
- tap location converted to a Gaussian heatmap
- heatmap aligned to image coordinates, then downsampled to latent resolution
- Uses two channels:
scare_heatmaptap_flag
Training spec
v15 scare run (rollout = 2, history = 8):
obs_rgb: (B,8,3,256,256)
act_maps: (B,2,2,256,256) -> bilinear -> (B,2,2,32,32)
target_rgb: (B,2,3,256,256)
z_hist: (B,8,8,32,32) # AE(obs_rgb)
z_target: (B,2,8,32,32) # AE(target_rgb)
cond_t = cat([
reshape(z_hist_t, B,64,32,32), # 8 history * 8 latent channels
action_t(B,2,32,32), # [scare_heatmap, tap_flag]
sigma_ctx_t(B,8,32,32) # context-noise channels (when ctx_noise_max>0)
], dim=1) # -> (B,74,32,32)
denoiser input = cat([x_noisy_t(B,8,32,32), cond_t], dim=1) # (B,82,32,32)
- Prediction target: preconditioned clean latent
x0(x_hat) via EDM wrapper; notepsand notv. - Training sigma sampling:
sigma ~ LogNormal(p_mean=-1.2, p_std=1.2), clamped at1e-3, withsigma_data=0.154weighted EDM MSE. - Inference sampler: Euler EDM with Karras schedule (
rho=7), typicallysteps=4,sigma_max=1.0,sigma_min=0.002. - Rollout-2 training: optimize two future steps together, and for step 2 gradually switch from ground-truth history to model-predicted history (
0 -> 0.5 @10k -> 1.0 @50kin v15).
Model size
- AE: 13.6M parameters
- EDM (UNet): 47.7M parameters
- Total: \~61M parameters, \~900 MiB GPU memory at inference
- Runs comfortably on a T4
Deployment
- server-side (Modal T4 GPU)
- browser-side (ONNX/WebGPU)
Notes on Deployment
I wanted to give an option to run this locally with WebGPU, so I built 2 demos:
- Server-side (Modal GPU + WebSocket)
- Client-side (ONNX + WebGPU)
One practical lesson: keep sampler defaults identical across demos. I did lose some time debugging what turned out to be viewer mismatches.
What's left
The point of this experiment was to validate whether the screen itself can be the action space, and I think it can. The main thing still unresolved is long-horizon consistency. If I were to pick next steps, they'd be longer closed-loop runs and better memory beyond a short latent window.
I was already doing closed-loop rollout training before I came across Self Forcing, which formalizes the same intuition: train on your own outputs, not only clean history. That's a good area to explore.
Interactive video for art and content is still underexplored while most energy is going toward game/RL benchmarks. To me, the more interesting direction is something closer to Bandersnatch, but generated in real time instead of assembled from pre-filmed branches.
References
- DIAMOND (Alonso et al., 2024)
- GameNGen (Valevski et al., 2024)
- Oasis (Decart, 2024)
- EDM (Karras et al., 2022)
- Self Forcing (Huang et al., NeurIPS 2025)
- StateSpaceDiffuser (Savov et al., 2025)